URL
URI 和 URL
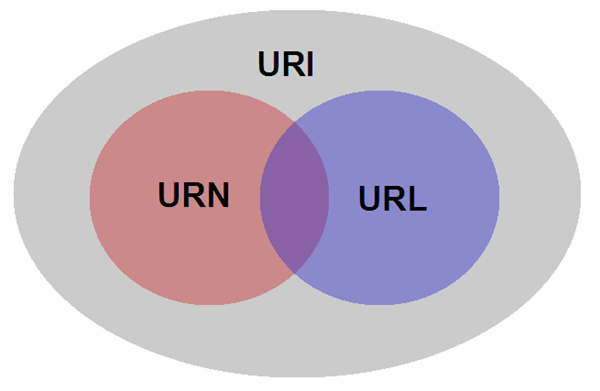
统一资源标志符(英语:Uniform Resource Identifier,缩写:URI)在电脑术语中是用于标志某一互联网资源名称的字符串。
用户可以通过 URI 对网络中的资源使用特定的协议进行交互操作,URI 格式如下:
hierarchical part
┌───────────────────┴─────────────────────┐
authority path
┌───────────────┴───────────────┐┌───┴────┐
abc://username:password@example.com:123/path/data?key=value&key2=value2#fragid1
└┬┘ └───────┬───────┘ └────┬────┘ └┬┘ └─────────┬─────────┘ └──┬──┘
scheme user information host port query fragment
urn:example:mammal:monotreme:echidna
└┬┘ └──────────────┬───────────────┘
scheme path
URL 是最常见的 URI 形式
统一资源定位符(英语:Uniform Resource Locator,缩写:URL,或称统一资源定位器、定位地址、URL 地址)俗称网页地址,简称网址,是因特网上标准的资源的地址(Address),如同在网络上的门牌。
URL 用于标识互联网资源,缺点是当期资源存储位置发生变化后必须对相应的 URL 进行改变。URN 也是 URI 的实现,通过名称来标识不依赖位置
统一资源名称(英语:Uniform Resource Name,缩写:URN)是统一资源标识(URI)的历史名字,它使用 urn:作为 URI scheme。
TODO:URL 的组成
URL 只能包括英文字母、数字和某些标点符号$ - _ . + ! * ' ( ) ,。
URL 标准格式:[协议类型]://[服务器地址]:[端口号]/[资源层级UNIX文件路径][文件名]?[查询]#[片段ID]
URL 完整格式:[协议类型]://[访问资源需要的凭证信息]@[服务器地址]:[端口号]/[资源层级UNIX文件路径][文件名]?[查询]#[片段ID]
其中[访问凭证信息]、[端口号]、[查询]、[片段 ID]都属于选填项。
http://www.example.com:8042/over/there?name=ferret#nose
- 请求协议:
http - 主机(域名):
www.example.com - 请求端口:
8042 - 请求路径:
/over/there - 查询参数:
name=ferret - 锚点:
nose
JavaScript URL 编码
在 URL 中包含中文等特殊字符时不同的浏览器、不同的请求方式浏览器会采用不同的编码方式对 URL 进行编码; 为了解决这种混乱的编码规则,我们可以使用 JavaScript 对 URL 进行编码,避免浏览器进行编码;
escape() & unescape()
返回一个字符串的 Unicode 编码值,除了 ASCII 字母、数字、标点符号@ * _ + - . /以外其它所有字符进行编码;
很古老的方法,已经不推荐使用,使用的时候需要注意:
- escape()不对"+"编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格
- 无论网页的原始编码是什么,一旦被 Javascript 编码,就都变为 unicode 字符
encodeURI() & decodeURI()
对整个 URL 进行编码,除了常见符号以外,对于在网址中有特殊意义的符号; / ? : @ & = + $ , #也不进行编码;
编码后输出 UTF-8 形式,并且每个字节前加上%;
不对单引号'进行编码;
encodeURIComponent() 和 decodeURIComponent()
用于对 URL 的个别部分进行编码;
会对; / ? : @ & = + $ , #这些符号进行统一编码;
JavaScript length 字符长度问题
3.3JavaScript 与 UCS-2
- JavaScript 字符串字符长度相关,https://segmentfault.com/a/1190000007992410 UCS(Universal Character Set)通用字符集,使用 ISO 制定的标准字符集 ISO 646, UCS-2 是 ISO 646 编码字符集的字符编码,使用两个字节表示一个字符,只能覆盖 Unicode 编码字符集的基本平面。
与此同时由 Xerox、Apple 等软件制造商于 1988 年组成的统一码联盟也在开发统一码项目。 很快两个组织意识到不需要两套标准,然后决定合并工作成果,共同完成 Unicode 的编制工作。 http://www.ruanyifeng.com/blog/2014/12/unicode.html
Unicode 分为 17 个平面进行编码,第一个平面用于存放最常用的字符叫做基本平面,码点位置为 U+0000 到 U+FFFF。 其它字符放在另外 16 个平面,叫做辅助平面,码点位置为 U+010000 一直到 U+10FFFF。
UCS-2 这种使用两个字节的表示一个字符的字符编码明显不能满足需求,于是就出现了 UTF-16 UTF-32 UTF-8 等一系列字符编码。 UTF-16 是 USC-2 的超级,基本平面字符同样使用两个字节表示,其它平面字符使用四个字节表示。 UTF-8 是变长字节编码方案,使用 1-4 个字节表示一个字符。 另外还有 UCS-4:使用四个字节,UTF-32 等同于 UCS-4,UCS-4 是 UTF-32 的超级;
JavaScript 使用 Unicode 字符集,但是使用 UCS-2 编码方案 因为 JavaScript 出现的时候还没有 UTF-16,所以 JavaScript 使用的是 UCS-2 编码; 由于采用 UCS-2 编码造成了中所有字符都是两个字节,对应汉子这种每个字符需要两个以上字节的字符就会被当做两个字节处理