前端开发编码
一、HTML 编码
设置 HTML 编码有以下方式:
- meta 元素:通常使用
meta元素<meta charset="gb2312">定义,或者使用http-equiv和content属性定义<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">。H5 规范推荐使用<meta charset="UTF-8">替换http-equiv; - HTTP 响应头:
Content-Type:text/html; charset=utf-8,响应头的优先级要高于meta标签。meta标签和响应头设置的编码应该保持一致,可以在这W3C Internationalization Checker检查响应头的编码设置和页面国际化支持情况。 - BOM(byte-order mark 字节顺序标记):BOM 是在文件字节序列开头的一段用来区分 Unicode 的编码方式的字节。BOM 相对于响应头和 meta 元素有更高的优先级(除 IE10,IE11 外)。
1.1 BOM
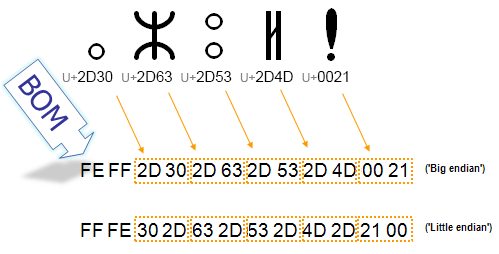
BOM 头是用来标记 UTF-16 编码的字节序列顺序的,UTF-16 使用两个字节来编码,根据这两个字节的排列顺序有两种编码方式:
- 一种方式叫做big-endian,
- 另外一种方式叫做little-endian,把第二个字节在前面
开头的 BOM 为U+FEFF代表使用 big-endian,开头为U+FFFE代表使用little-endian。
始终想不明白为什么需要 little-endian,为什么要把第二个放到前面?
在 UTF-8 编码中 BOM 头不是必须的,因为不像 UTF-16 有两种排列方式;UTF-8 的 BOM 头为EF BB BF。
大多数时候我们不需要关心 BOM,一些编辑器会默认添加 BOM 头,一些编辑器则会根据你的配置来添加。 BOM 可以提供可靠的编码描述,因为它简洁稳定,即使是在非网络环境没有 HTTP 响应头的情况下。 应该保证 BOM 头和 meta 标签的一致性,
因为 BOM 的优先级高于 HTTP 响应头,在无法控制 HTTP 响应头的情况下使用 BOM 来做编码声明也许是一个好办法。
1.2 文档字符集(Document Character Set)和转义字符(Character escapes)
HTML 和 XML 文档的字符集为 Unicode,即浏览器内部在处理 HTML 和 XML 时会将内部文本转换为 Unicode。 所以 HTML 和 XML 只能处理Unicode字符集内定义的字符。 在 HTML 中你可以使用任何字符编码,但是必须对使用的编码必须进行正确的声明,并且该编码的字符集必须是 Unicode 字符集的一个子集。
转义字符也叫实体字符,在 HTML 中可以通过转义字符使用ASCII 字符表示任意Unicode 字符。 转义字符的主要用途有以下两种:
- 语法字符的显示,例如
< (<)> (>)& (&),在 HTML 中直接使用这些字符会引起语法错误。 - 展示文档所使用字符集不包含的字符,例:文档编码为
GB2312要展示字符©就可以使用©。
标签中的转义字符有数值式和命名式两种形式:
- 数值字符索引:
&#entity_number;,以&#开始,;结尾,中间实体变化的值为索引的 Unicode 字符的码点- 十进制:
  - 十六进制:
 ,x 代表接下来是一个 16 进制数
- 十进制:
- 命名字符索引:
&entity_name;,以&开始,;结尾,中间为规范的命名- 是 HTML 规范定义的一部分,只包含了 Unicode 字符集的一部分
- 相对数值字符索引更加语义化,有更好的可读性
- 区分大小写

二、样式文件编码
大多数情况下 CSS 文件中不会出现非 ASCII 字符,也就是大多数时候我们不需要考虑 CSS 文件的编码问题。
当然也有例外,例如:content属性中使用汉字。这时我们就需要对 CSS 文件的编码进行正确的声明或设置。
在 CSS 文件起始位置使用@charset "charset-name";可以设置样式文件的编码。
注意@charset属性必在样式文件最前面,即使声明前有空格或注释声明均不生效。
另外,在link下使用charset属性设置编码是 HTML 4.0.1 规范的方法,在 HTML5 规范中已经被废弃,建议停止使用。
例:<link href="http://gameweb-img.qq.com/css/common.css" rel="stylesheet" charset="gb2312" >
CSS 文件的编码解析路径如下,优先级递增:
HTML 默认编码 < charset 属性 < HTTP 响应头 < BOM 头
三、脚本文件编码
JavaScript 采用的是 Unicode 字符集,即在 JavaScript 运行时会将源码转化为 Unicode。
保证 JavaScript 不出现乱码的情况可以有两种方式:
- 保证使用正取的字符编码进行解码,即声明正确的字符编码。
- 将源码内的非 ASCII 字符进行转义。
3.1 设置正确的编码
外部脚本的编码设置有以下几种方式,优先级递增:
- 默认编码:HTML 文档加载的 JavaScript 脚本默认按照 HTML 文档编码进行解码;
- charset 属性:在
script标签中使用charset属性声明,例:<script src="test.js" charset="gb2312"></script>; - HTTP 响应头:在脚本文件的 HTTP 响应头中进行设置,例:
Content-Type:application/javascript; charset=gb2312; - BOM 头:脚本文件 BOM 头相比 HTTP 响应头有更高优先级,同样在 IE 下支持有问题;
3.2 JavaScript 转义
JavaScript 在运行的时候会将源码转换为 Unicode,我们在代码发布之前将源码中的非 ASCII 字转换为 Unicode 序列,那么在 JavaScript 运行的过程中就不会存在解码错误的问题了。
转义序列以一个反斜线\开头,有以下几种转义方式:
- 16 进制转义字符:
\x03,只有两位 16 进制数,只能编码从 U+00 到 U+FF 的有限数量的代码点; - Unicode 转义字符:
\u0200,后跟 4 位 16 进制数,可用编译基本平面的全部码点(U+0000 到 U+FFFF)。要表示其它平面的字符,可用使用两个连续的 Unicode 转义序列; - 代码点转义字符:
\u{001100},ES2015 规范提供了可以支持整个 Unicode 字符集的转义方式,
JavaScript 字符串的转义我们可以通过前端自动化工具来完成,例如 UglifyJS 的ascii_only: true。
四、异步请求编码
AJAX(Asynchronous JavaScript And XML)JavaScript 异步网络请求,
以下结果为测试所得,暂未找到相关文献:
- 文档内部脚本异步请求解码规则与文档默认编码无关,默认编码为 UTF-8,受响应头和 BOM 影响;
- 外部脚本,异步请求解码规则与脚本运行编码无关,默认编码为 UTF-8,受响应头和 BOM 影响;
- BOM 优先级高于响应头;
参考
Declaring character encodings in HTML The byte-order mark (BOM) in HTML Using character escapes in markup and CSS 通用字符集 Unicode