字符编码基础知识
开发过程中经常遇到各种编码问题,只要把编码调整一致就可以解决问题。然而并没有对编码有一个很清楚的了解,于是查了一些资料,用自己的话总结了一下,梳理了一下概念和关系。有不对的地方欢迎大家提出拍砖,轻拍谢谢。
What & Why
计算机存储单元bit只能有两种状态,只能存储 0 和 1,通过 0 和 1 的组合代表不同的信息; 这些 0 和 1 的组合人是不能够直接理解的,所以要把这些这些 0,1 进行转换,转换成文字、声音、图像等等,反之一样要把文字图片等转换成 0 和 1 进行存储和传输;
在信息的存储和网络传输的过程中我们要把信息转换成 0 和 1 的序列,这个转换过程就是编码(Encoding) 从硬盘和网络中读取的到的 01 序列要进行逆转换才能得到我们能够理解的信息,这个逆转换过程就是解码(Decoding)
基本概念
- 比特(bit):是计算机信息中的最小单位,对应一个物理存储,一个二进制位
- 字节(Byte):计算机中信息计量的一种单位,每 8 个位(bit)组成一个字节(Byte)
- 字符(Character):是组成单词和语句的基本单位,它可以是英文字母、拉丁字母、汉字、符号等
- 字符集(Character Set):是一系列特定用途字符的集合
- 编码字符集(Coded Character Set):是一个字符集合,集合中的每个字符都已经被分配了一个唯一的数值,这个值就是码点(Code Point)
- 编码(Encoding):信息从一种形式或格式转换为另一种形式的过程
- 解码(Decoding):编码的逆过程
- 字符编码(Character Encoding):字符是以字节(bytes)的形式存储在电脑中的,字符编码提供了字节和字符之间的映射关系,编码和解码必须遵守同一套字符编码,如果字符编码不一致就有可能出现乱码
字符编码的发展的几个阶段
第一阶段:ASCII 及 ASCII 扩展
美国人发明了计算机,也创造了第一套字符编码ASCII(American Standard Code for Information Interchange 美国信息交换标准码)。
每 8 个晶体管为一组,组成一个 Byte,可以产生 256 种组合;美国人使用其中的 128 种组合指定了 ASCII,占用了 0-127 段;
占用一个 Byte 中的后七位,第一位为 0,例如 A 是 65(01000001)、B 是 66(01000010);包括终端状态、标点符号、数字、英文大小写字母;
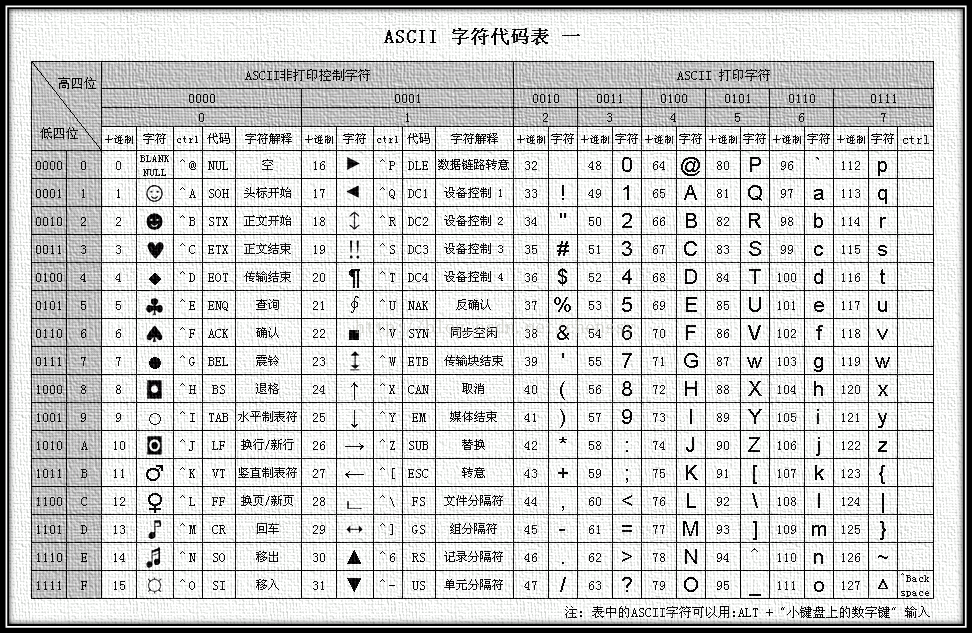
但是 ASCII 只能表示显示 26 个基本拉丁字母、阿拉伯数字和英式标点符号;然后欧洲人不乐意了,字母符号不够用啊。
欧洲人决定在 ASCII 上扩充了表格符号、计算符号、希腊字母和特殊的拉丁符号;0-127 段和 ASCII 完全相同,占用了 128-255 这段存储空间。称为EASCII(Extended ASCII 延伸美国标准信息交换码)

在这个阶段每个字符在计算机存储和传输中使用一个字节进行编码。
第二阶段:百花齐放
很快中国、日本、韩国等等很多国家都要使用计算机,所以 EASCII 也根本够用,所以就各自制定了一些列字符集,以下几个为应用较多的几个中文字符集:
GB2312:简体中文字符编码,共包含 7445 个字符,6763 个汉字和 682 个其他字符(拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母),包含 ASCII,ASCII 部分使用一个字节进行编码,汉字使用两个字节进行编码;BIG5:台湾繁体字符编码,同样使用两个字节编码,,共收录 13,060 个汉字及 441 个符号;GB13000:大陆为了追赶 Unicode 的世界潮流定制的编码,据说是把 Unicode1.1 拿过来改了个名;GBK:GB2312 的扩展,微软利用GB2312未使用的空间收录了GB13000的所有字符制定的编码方案,向下兼容GB2312,仍然使用两个字节;
一个字节(Byte)最多可以有 256(2 的 8 次方)中组合方式,应对亚洲图形文字明显不够用,所以采用两个字节长度进行编码。 以上只是中国折腾出来的东西,其它国家应该一样很热闹多产。
第三阶段:万宗归一-通用字符集
很快这种百发齐放的繁荣就暴露了出了问题,各个国家都在定制自己的字符编码,乱成一锅粥了,同一个二进制在不同的编码方案下表示的是不同的字符;
这时一些国际组织站出来做编码统一这件事,最后制定了Unicode(国际码),
Unicode 从 0 开始为每个符号指定了一个编号,叫做“码点”;
通常在表示一个 Unicode 值的 16 进制数前面加上U+,例如码点 0 的符号就是 nullU+0000 = null;
Unicode 的码点取值范围为U+000000-U+10FFFFF共 1114112 个可用码点,但是并未全部使用;
Unicode 平面 Unicode 并不是采用从小到大、从前到后这种方式对字符进行编码的,而是将 1114112 个可用码点划分成了 17 个平面;
- 平面 0:从
U+0000到U+FFFF - 平面 1:从
U+10000到U+1FFFF - 平面 16:从
U+100000到U+10FFFF的代码点
可用看出 Unicode 使用第一个字节作为平面编码,其余两个字节进行字符编码,每个平面可用编码 65536(2^16)个字符。 其中第平面 0 比较特殊,包含了大多数最常用的语言字符和符号,称为基本平面(BMP) 其它 16 个平面称为辅助平面,具体平面分布可用参考Unicode 字符平面映射。
第四阶段:完善
Unicode 是一个通用字符集,对世界上大部分文字系统进行了整理、编码,解决了编码字符集不统一的问题。
但是 Unicode 只制定了字符的码点,没有定制字符编码方案,
比如汉字“中”的码点十六进制数是4E2D,转换为二进制是100111000101101共 15 位,至少需要 2 个 Byte,但是也可以使用 3 个或 4 个 Byte;
那么问题来了:
- 划分问题:计算机无法确定使用几个字节解码成一个字符;
- 流量问题:如果统一使用四个字节编码一个字符,那么对于英文字母和数字这种使用一个字节就可以编码的字符是极大的浪费;
为了解决这个问题很多厂商都有自己的 Unicode 编码方案,最后形成了多种 Unicode 编码实现方案,UTF-8 是互联网使用最广的一种方式;
- UTF-8:变长编码方案,1~4 字节变长编码方案
- 128 个 ASCII 字符只需要一个字节
- 拉丁文、希腊文等其他字母类字符使用两个字节
- 日韩等大部分国家文字使用三个字节
- 他生僻字使用四个字节
- UTF-16:使用 2 字节和 4 字节变长编码
- 128 个 ASCII 字符需两个字节编码
- 其他字符使用四个字节编码
- UTF-32:所以字符使用 4 字节对应一个码点
UTF-8 编码方案
UTF-8 是 Unicode 的实现方式之一,UTF-8 是一种变长的编码方式
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 unicode 码,所以对于英语字母,UTF-8 编码与 ASCII 编码是完全相同的
- 对于 n 字节的符号,第一个字节的前 n 位都设为 1,第 n+1 为设为 0,后面字节的前两位一律设置为 10。剩下的位提取出来即为这个符号的 Unicode 编码
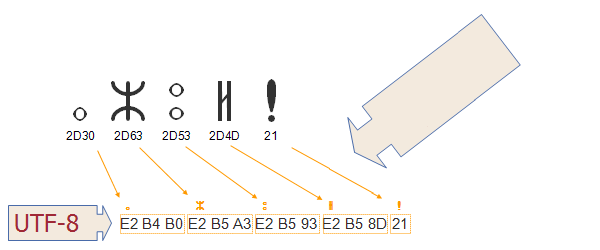
例子:以“中”字为例
| Unicode 编码 | 4E2D(0100 1110 0010 1101) |
|---|---|
| 需要 3 个字节来存储,即为 | 1110 xxxx 10xx xxxx 10xx xxxx |
| 填充后 | 1110 0100 1011 1000 1010 1101 |
| 转换为十六进制 | E4B8AD |
“中”的 Unicode 编码为4E2D,UTF-8 编码为E4B8AD,二者的编码并不相同,是通过程序转换的
字符集、编码字符集和字符编码
字符集是一系列特定用途字符的集合,编码字符集中的每个字符都被绑定了一个唯一数值,字符编码是编码字符和计算机字节的映射,如下图:
 字符编码主要用于解决存储和传输的问题,而编码字符集就是给字符集里面每个字符提供一个序号。
字符编码主要用于解决存储和传输的问题,而编码字符集就是给字符集里面每个字符提供一个序号。
同一个字符集可能有多种编码字符集,同一编码字符集还可能有多种不同的字符编码
 有些编码字符集合字符编码是一体的例如:GBK ASCII。
有些编码字符集没有规定字符编码方案例如 Unicode 只是一个编码字符集。
Unicode 的字符编码又有多种字符编码实现方案例如:UTF-8、UTF-16 等。
有些编码字符集合字符编码是一体的例如:GBK ASCII。
有些编码字符集没有规定字符编码方案例如 Unicode 只是一个编码字符集。
Unicode 的字符编码又有多种字符编码实现方案例如:UTF-8、UTF-16 等。
参考
Character encodings for beginners Character encodings: Essential concepts Unicode - 维基百科 字符编码笔记:ASCII,Unicode 和 UTF-8 字符编码的前世今生